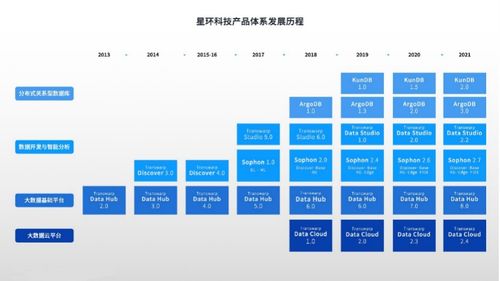
數客調研 | 圍觀,基礎架構廠商與人工智能的武林恩怨(上) 人工智能基礎軟件的開發迷局
在人工智能技術浪潮席卷全球的今天,其發展早已超越算法的單點突破,演變為一場涉及計算、存儲、網絡及軟件棧的全面體系化競爭。在這場沒有硝煙的“武林大會”中,傳統的基礎架構廠商與新興的AI原生力量之間,正上演著一場關于技術路線、生態主導與商業版圖的復雜博弈。本系列上篇,我們將聚焦于這場恩怨的起點與核心——人工智能基礎軟件的開發迷局。
一、舊盟主與新挑戰者:生態位之爭
傳統的基礎架構巨頭,如英特爾、英偉達(在GPU領域早已超越傳統定義)、VMware、紅帽等,憑借數十年在芯片、服務器虛擬化、操作系統及云基礎軟件領域的深厚積累,構筑了堅固的“護城河”。他們的核心優勢在于穩定性、大規模企業級部署經驗以及與現有IT體系的深度融合。人工智能,特別是深度學習,催生了一套全新的計算范式:以GPU/TPU等加速計算為核心,對大規模分布式訓練、海量非結構化數據處理、彈性異構資源調度提出了前所未有的需求。
這催生了一批“新挑戰者”:以PyTorch、TensorFlow為代表的AI框架開發者;專注于AI算力調度與管理的軟件平臺(如Kubernetes在AI領域的延伸與定制化);以及眾多提供向量數據庫、特征平臺、模型部署與服務的初創公司。他們從AI應用的需求痛點出發,試圖重新定義底層軟件的架構與接口。新舊勢力在“AI基礎軟件”這一交匯點上短兵相接——前者力圖將AI能力融入既有龐大體系,講求“平穩過渡”;后者則希望以AI為中心重構堆棧,追求“極致性能與敏捷”。
二、開發之困:兼容、性能與掌控力
基礎架構廠商進軍AI基礎軟件開發,首要面臨三重矛盾:
- 兼容性與顛覆性的兩難:為了照顧現有客戶的海量存量資產(如x86架構服務器、特定存儲系統),其AI軟件方案往往選擇兼容現有接口和協議,這有時意味著無法充分利用為AI定制的最新型硬件特性(如特定AI芯片的指令集、高速互聯技術)。而AI原生軟件則輕裝上陣,常為特定硬件或場景做深度優化,雖在局部實現性能突破,卻可能帶來新的碎片化與鎖定風險。
- 通用平臺與專用優化的平衡:傳統廠商的軟件平臺(如云管平臺、容器平臺)設計初衷是“通用”,管理從Web服務到數據庫的各種負載。而AI工作負載,尤其是大規模訓練任務,具有周期長、資源需求波動大、對網絡帶寬和延遲極度敏感等特點。將AI負載簡單塞入通用平臺,常導致資源利用率低下或性能不達標。因此,是增強現有平臺還是另起爐灶開發專用AI平臺,成為戰略抉擇。
- 開源與閉源的掌控博弈:AI基礎軟件領域,開源生態(如Kubernetes、PyTorch)已成為創新的主引擎和事實標準。傳統廠商既要積極參與和貢獻開源項目以保持影響力與兼容性,又希望通過發行版、企業增強功能或獨家集成來構建商業壁壘。如何在不被開源洪流“稀釋”價值的又能借力其生態快速擴張,是一門精妙的藝術。以英偉達為例,其通過CUDA生態的軟硬件深度綁定,成功構筑了近乎壟斷的地位,展示了閉源軟件與專屬硬件結合的巨大威力,但這并非所有廠商都能復制的路徑。
三、合縱連橫:聯盟、分化與標準之戰
面對迷局,“武林”中各派勢力并非單純對抗,合縱連橫成為常態。
- 硬件與軟件的深度耦合:英偉達的CUDA+GPU模式是典范。如今,更多芯片廠商(包括傳統CPU巨頭和新興AI芯片公司)都在大力投資其配套的編譯器、算子庫、運行時等基礎軟件,力求打造“全棧優勢”。基礎架構廠商若不能在此層面深入,則可能淪為“純粹的硬件提供商”。
- 云廠商的降維整合:大型公有云廠商(如AWS、Azure、GCP)憑借其覆蓋IaaS到AI服務的全棧能力,正成為重要的整合者。它們既能自研AI芯片與基礎軟件(如AWS的Trainium、Inferentia芯片及Neuron SDK),也廣泛集成第三方最佳方案,為客戶提供“一站式”體驗,對傳統軟硬件解耦銷售的模式形成壓力。
- 開源社區的標準爭奪:圍繞模型格式(如ONNX)、中間表示(如MLIR)、調度接口等,各大廠商在開源基金會中展開激烈角逐,力求將自身技術推進為行業標準,從而在生態中占據有利位置。
上篇軟件定義AI基礎設施的時代已至
人工智能的基礎軟件開發,已不再是簡單的工具創造,而是定義未來AI計算形態、分配產業鏈價值的關鍵戰場。傳統基礎架構廠商憑借工程化、穩定性和企業級服務能力深度介入,而AI原生力量則以對需求的敏銳洞察和架構創新不斷挑戰現狀。這場“恩怨”并非零和游戲,其核心在于誰能更快地融合技術創新與產業現實,打造出既高效又易用、既開放又可持續的AI基礎軟件棧。
競爭剛剛升溫,融合已在發生。在下篇中,我們將把目光投向市場落地、商業模式與未來格局的展望,看這場“武林恩怨”將如何塑造智能時代的底層面貌。
如若轉載,請注明出處:http://www.clblog.cn/product/72.html
更新時間:2026-04-12 00:16:04